Betting against the Machine God

Frontier models can write poetry, generate working code, and prove mathematical theorems and then, without warning, become strangely incompetent at things that feel adjacent. They are “jagged”, which means their capability profile is not evenly distributed.
There are two ways to read this: One view says the jaggedness is temporary - scale and better methods will smooth it out. Capability converges, sufficiently powerful systems do everything well, training context becomes increasingly irrelevant, one dominant general intelligence emerges and all else is a wrapper around it. The other view says the jaggedness is structural and capability remains shaped by training context because the entire current AI paradigm shows insufficient generalisation ability. In this world general systems keep getting better at general tasks, but domains with genuinely different constraints keep rewarding specialized training because the error costs, feedback loops, workflows & data are different.
Most AI discourse implicitly assumes the first view. The "models are commoditizing, so bet on the application layer" argument is a version of it. But that argument contains a contradiction. If models are commoditizing because capability is converging, and convergence continues to its natural conclusion: A god-like model that excels at everything (the public-facing stance of current frontier labs1), then the application layer necessarily compresses too. The model does everything well, hence executes entire workflows correctly and reliably. Integration, governance and monitoring become standardized plumbing around this oracle with no differentiation between application players.
The "bet on apps" advice therefore must implicitly assume convergence is real enough to commoditize models but somehow stops before it commoditizes applications, horizontal convergence happens but vertical convergence does not but that's not a coherent position. Either capability converges all the way, and the model layer captures all verticals and the entire stack within those verticals, or the environment keeps mattering and specialized training keeps producing differentiated capability. You can believe one or the other, but not both.
Within the current paradigm, we're betting on structural. The reason comes from how training works. The story of 2020–2024 was pre-training at scale and involved more data, more compute, and capabilities improving together. But pre-training is only the foundation. Everything after, continued training on domain distributions, instruction tuning, and reinforcement learning, works differently. These later stages don't lift all boats because they make choices that privilege some capabilities while suppressing others.
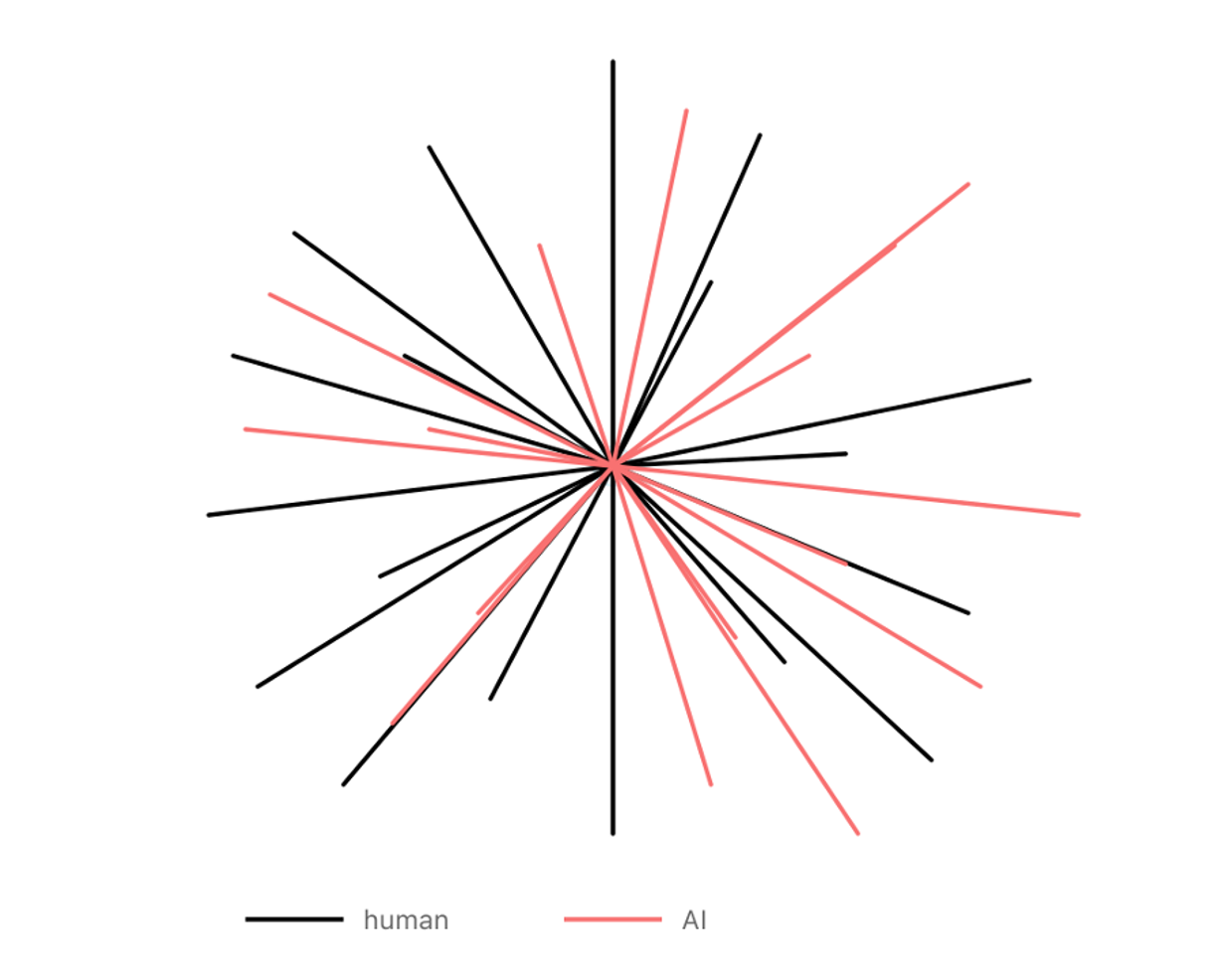
Figure 1. Human intelligence (black) vs AI intelligence (coral) – both are jagged, but differently so, fundamentally due to having evolved in different environments. Adapted from Karpathy 2
Once you move past generic next-token prediction and start optimizing for particular outcomes, you're shaping what kind of intelligence the model becomes. The data distributions you choose, the reward signals you design and the benchmarks you evaluate against are selection pressures.
In clinical medicine the gap between "benchmark performance" and "operational capability" is particularly stark. On radiology quiz questions, models can look strong but when you move to messier clinical work such as integrating patient history, handling rare cases and staying calibrated about uncertainty performance falls apart in ways that would get a resident pulled from the rotation. These aren't properties you currently get for free from pre-training on internet text. Most of the value, and most of the danger, lives in this gap.
This is why there's a third viable configuration beyond "frontier lab" or "API wrapper" in certain verticals. Companies that start from open-weight foundations and build domain capability through heavy post-training tied to actual deployment. Frontier open-weight models are close enough on broad benchmarks that the foundation is good, trailing closed models by roughly three to six months on average3,4, but lack domain-specific capability. What they offer is the ability to train, push domain knowledge into the weights and build RL environments around real workflows to create a loop where deployment feedback becomes training signal. The compute is substantial, hundreds of top-end GPUs, but not 10,000+. Not frontier lab scale.
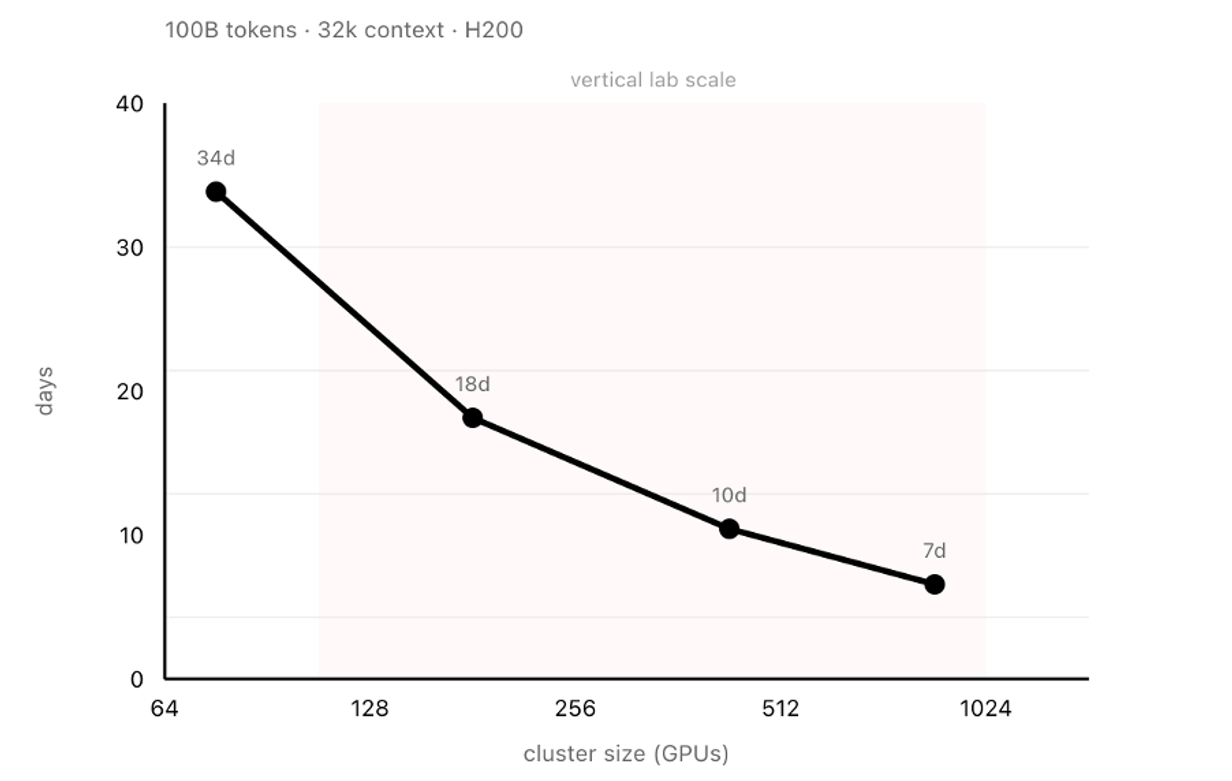
Figure 2. Time to train DeepSeek-V35 on 100B tokens at 32k context (H200 GPUs). Shaded region indicates vertical lab scale (128-1024 H200 equivalent GPUs). At 384 GPUs, supervised fine-tuning completes in under two weeks. Modelling RL as SFT plus on-policy generation of equal volume (as in GRPO), full iterations complete in approximately one month.
What makes this defensible is how deployment and training reinforce each other. A model deployed in a real clinical environment generates feedback that doesn't exist in any public dataset and shapes the next training iteration as environment design. Performance improves, deeper deployment becomes possible, richer feedback follows and the loop compounds. But it compounds under constraints because data must be heavily protected, labels are expensive, site variance is a concern, and continuous learning collides with change control. You don't get to ship weekly behaviour changes into regulated clinical pathways without a validation story and a as a result the flywheel is overall slower and more disciplined than in consumer software.
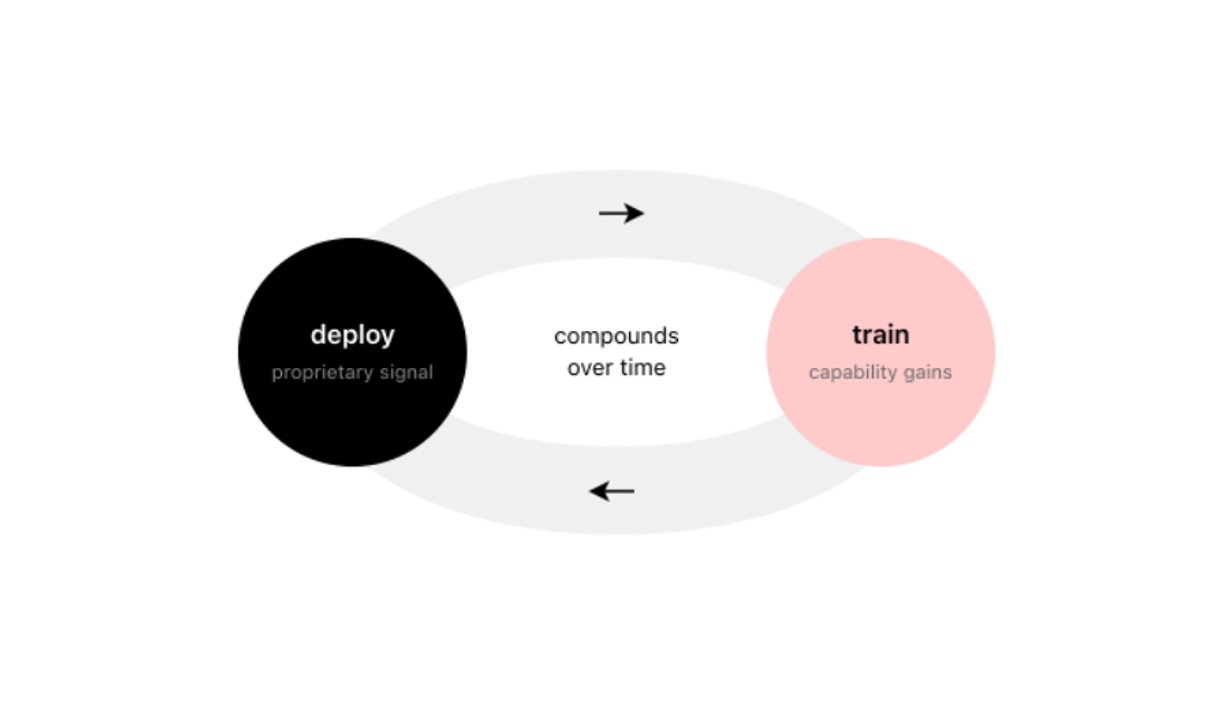
Figure 3. The deployment-training flywheel. Models deployed in clinical environments generate feedback that does not exist in public datasets. This feedback shapes the training environment for the next iteration, improving capability and enabling deeper integration. The loop compounds over time, creating differentiated capability that is difficult to replicate without equivalent deployment depth.
Two companies can start from the same open-weight base and, after enough iterations, end up with meaningfully different systems. The moat becomes less about the base model and more about the RL environment, the domain data pipelines, the regulatory approvals and trust relationships that took years to build.
There's also a capability barrier that's easy to underestimate. Full fine-tuning and RL at scale requires deep expertise in training, evaluation design, data & systems engineering, and the operational machinery to iterate quickly. The gap between "we fine-tune models" and "we train at frontier open-weight scale within clinical RL environments" is large. Most companies that want to be in this category can't assemble the technical capability to execute it.
Frontier labs can train powerful general models and enter any domain they choose. But they are unlikely to match the deployment depth of a focused vertical player across hundreds of regulated domains simultaneously.
Cohere provides some validation here: their CEO Aidan Gomez reported that revenue more than doubled in 2025, with The Information reporting $200 million in projected annualized revenue by mid-year, and a $500 million funding round at $7 billion valuation followed shortly after6,7. Their pivot was explicit, away from foundation model scale, toward tailored enterprise models across several industries. They're horizontal rather than vertical, but the economics work.
Cursor makes the case more sharply. They crossed $1 billion in annualized revenue in 2025 and raised at a $29.3 billion valuation8,9. They built Composer, their own model trained through reinforcement learning inside real coding environments, co-designed with the IDE, trained on hundreds of thousands of concurrent sandboxes, optimized for the specific feedback loops of software development. The result is frontier-level capability at four times the speed. They're vertical where Cohere is horizontal, but the logic is the same. Healthcare is where we're testing the thesis. It's one of the largest verticals for specialized AI investment, with spending reaching $1.5 billion in 202510.
For European healthcare systems there's also the question whether core clinical reasoning should run on models controlled by US providers, under different legal frameworks. For some institutions, the ability to audit and continuously validate the full system is a requirement that determines what they can deploy at all.
kaiko.ai is building on this thesis: a multimodal assistant for clinical experts that integrates pathology, radiology, genomics, and clinical text, alongside the execution environment, integrations & safety mechanisms that lets an agent function in a clinic. We're training from frontier-grade open foundations, which gives us commoditized base capabilities plus model access to close domain-specific gaps. Our work on Vortex-1, a frontier pathology VLM releasing in the coming weeks, suggests competitive performance is achievable through domain-focused training choices. This is our bet: that clinical capability requires clinical training, that the deployment-training loop creates compounding advantage and that the jagged capability profile in frontier models reflects something structural about how the current systems learn rather than a temporary gap that scale will automatically close.
We might be wrong. If we discover a better paradigm with more favourable generalisation properties compared to today's LLM stack, the jaggedness might smooth out faster than we expect. But if we're right about how capability develops in the mid-term, the winners in healthcare AI will be whoever closes clinical gaps through clinical deployment and training.
The AI market will consequently start to fragment more. General models will keep improving and serve broad applications well. But in verticals where feedback loops require deployment depth and error costs create real stakes, specialized training will produce significantly differentiated capability & real self-reinforcing moats.
We're betting against the machine God, against the view that a single general system will do everything well and that training environment stops mattering at sufficient scale.
Our systems are currently developed and tested in research and validation settings. Some of our products focus on supporting administrative and workflow processes and are not medical devices. Any future clinical decision support use would be subject to regulatory approval and compliance with applicable medical device frameworks, including the EU Medical Device Regulation (MDR).